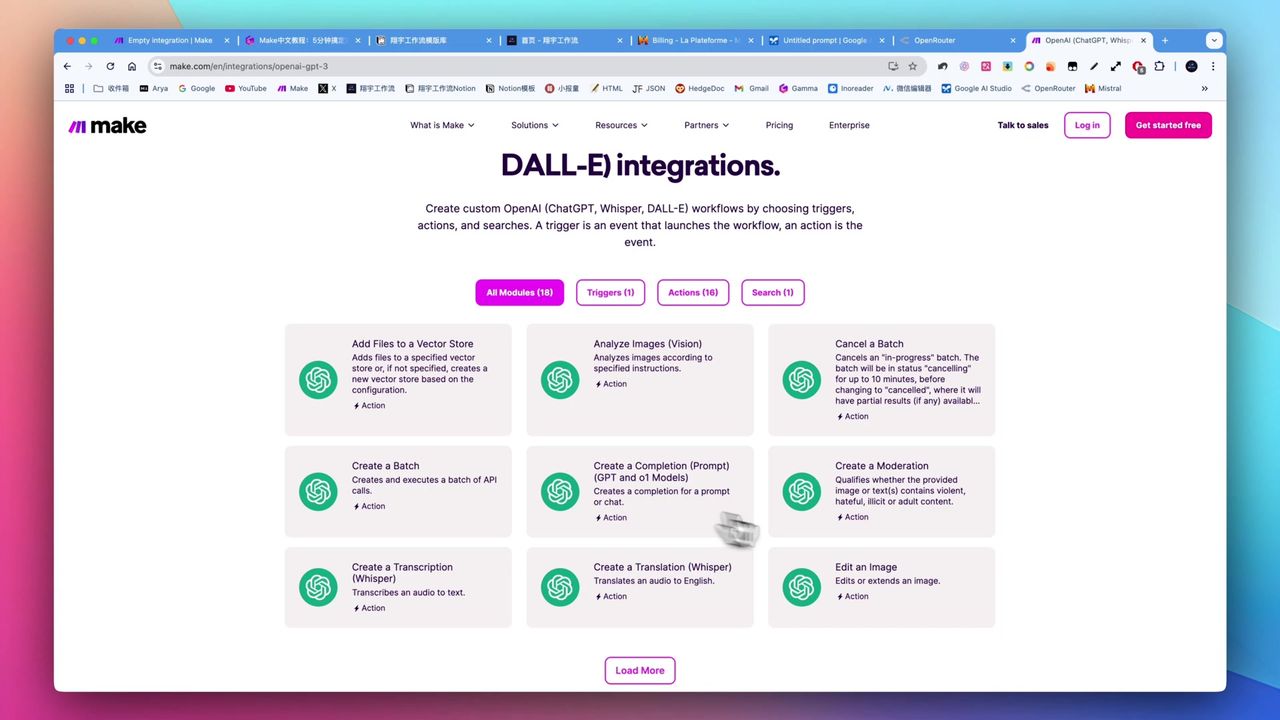
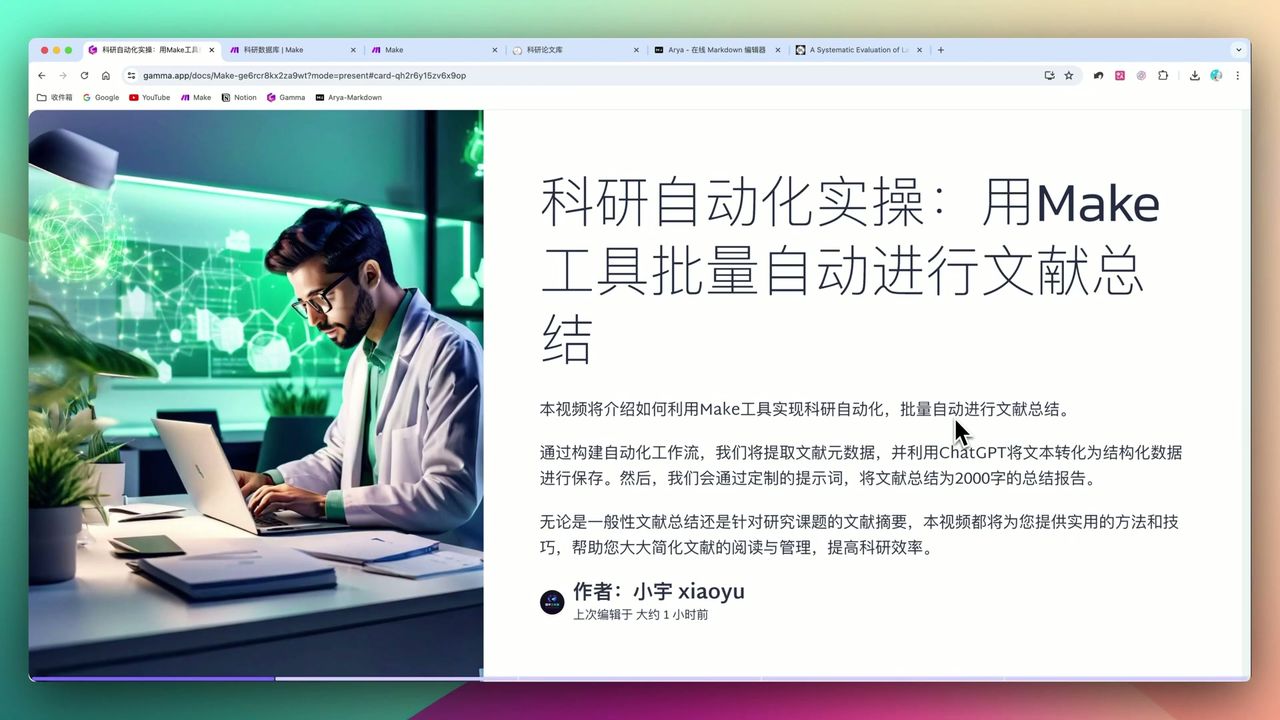
Make教程:用Apify自动采集YouTube视频数据构建Notion知识库
通过Make.com结合Apify的YouTube Scraper,自动采集视频标题、播放量、字幕等数据,批量归档到Notion,为AI内容创作打下数据基础。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
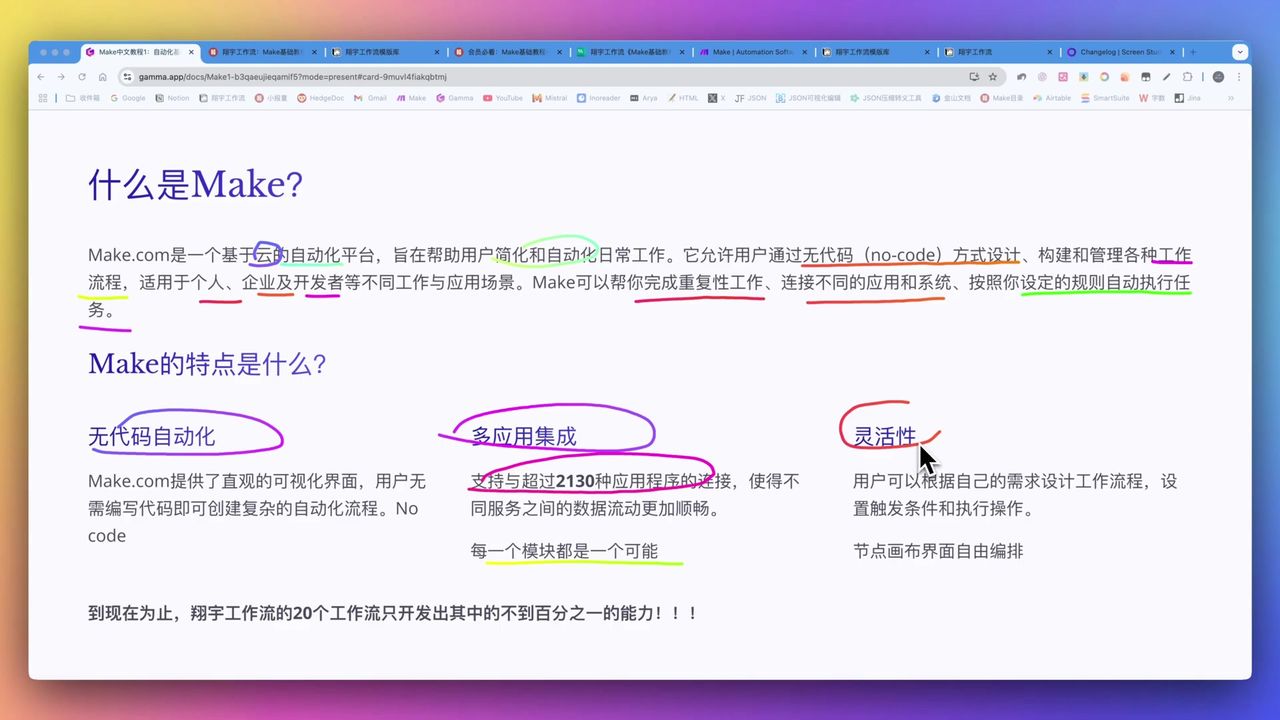
概述
这是一套为内容创作者和数据分析师量身定制的企业级视频数据采集方案。
通过结合Apify的强大爬虫能力、Make.com的逻辑编排以及Notion的数据库管理,实现YouTube视频信息的全自动归档:
- 输入频道 - 支持批量输入多个YouTube频道链接
- 数据采集 - Apify自动抓取视频元数据和字幕
- 数据处理 - Iterator拆分处理每条视频
- 智能过滤 - Filter处理无字幕视频
- 归档存储 - 自动写入Notion数据库
 数据库Schema设计,包含标题、URL、播放量等核心字段
数据库Schema设计,包含标题、URL、播放量等核心字段
核心决策因素
在选择视频数据采集方案时,需考虑:
- 配置门槛 - 是否需要写代码(本方案无需底层代码,但需理解JSON)
- 数据颗粒度 - 能否抓取字幕、封面图、点赞数等深层数据
- 容错机制 - 遇到无字幕视频时流程是否会中断
- 扩展性 - 能否轻松增加新的监控频道
技术规格参考
| 规格项 | 参数值 | 备注 |
|---|---|---|
| 核心中枢 | Make.com | 逻辑编排与数据流转 |
| 采集引擎 | Apify | YouTube Scraper Actor |
| 目标数据库 | Notion | 存储元数据与画廊视图 |
| 触发方式 | 手动/定时 | 支持批量或周期性更新 |
| 最大采集数 | 可配置 | 20/500/1000等 |
| 等待超时 | 120秒 | Make等待Apify完成 |
| 数据字段 | 标题/时长/播放量/点赞/字幕 | 覆盖核心元数据 |
| 时间过滤器 | thisWeek/thisYear | 按时间范围过滤 |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- Apify 账号和API密钥(apify.com)
- Notion 账号和数据库
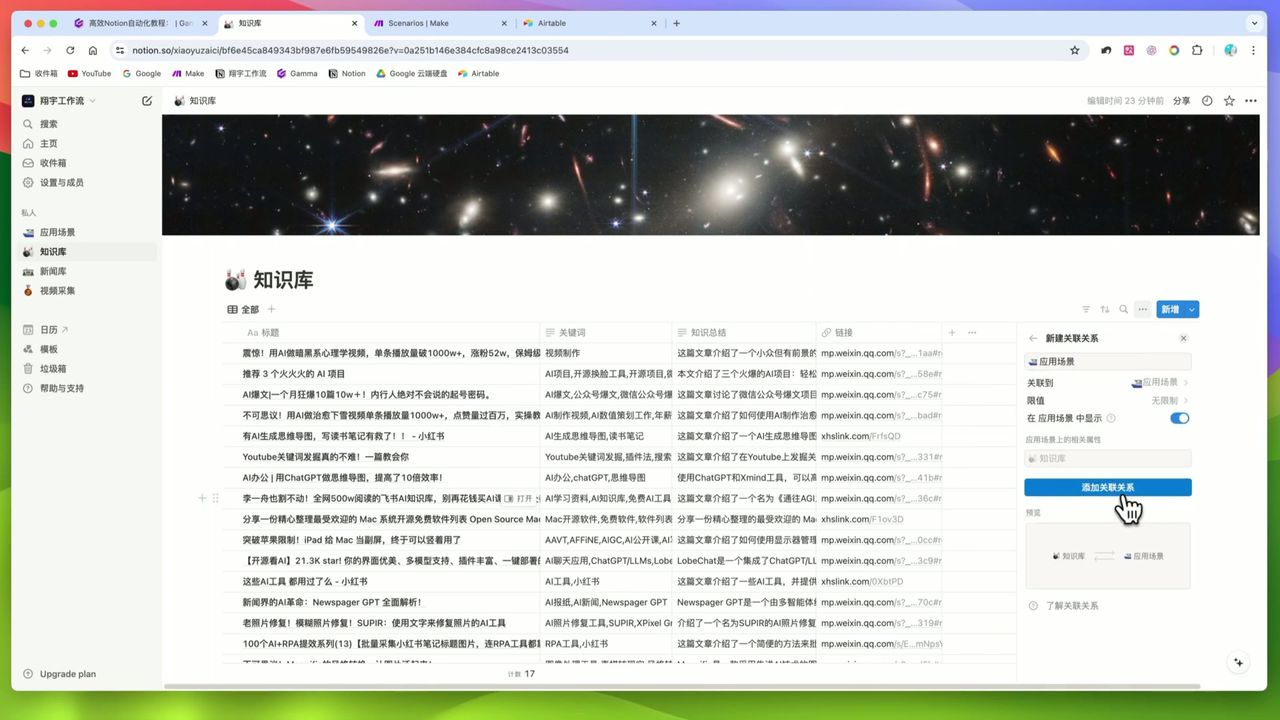
Notion数据库结构
创建视频资料库,包含以下字段:
- 标题 (Title) - 视频标题
- URL (URL) - 视频链接
- 频道 (Text) - 频道名称
- 播放量 (Number) - 观看次数
- 点赞数 (Number) - 点赞数量
- 时长 (Text) - 视频时长
- 发布日期 (Date) - 发布时间
- 封面图 (Files & Media) - 视频缩略图
工作流架构
核心模块
- Basic Trigger - 输入频道链接列表
- Iterator - 拆分多个频道逐一处理
- Apify Actor - 调用YouTube Scraper
- Filter - 过滤无字幕视频
- Notion - 写入数据库
 使用Iterator处理多个频道链接
使用Iterator处理多个频道链接
Step 1: 配置频道输入
使用Make的Basic Trigger配合Iterator,可以一次性输入多个频道链接:
操作步骤:
- 添加Basic Trigger模块
- 输入频道URL数组
- 添加Iterator拆分数组
重要:URL格式必须包含
https://或http://,否则传输给Apify会直接报错。
Step 2: 配置Apify采集
 通过JSON控制爬虫行为
通过JSON控制爬虫行为
在Make中添加Apify模块,配置YouTube Scraper Actor:
JSON参数示例:
{
"startUrls": [
{"url": "{{channel_url}}"}
],
"maxResults": 20,
"dateFilter": "thisWeek",
"downloadSubtitles": true
}关键参数说明:
maxResults- 最大采集数量dateFilter- 时间过滤(thisWeek/thisYear)downloadSubtitles- 是否下载字幕
Step 3: 配置数据映射
 将Apify数据对应填入Notion字段
将Apify数据对应填入Notion字段
重要:在配置Notion映射之前,必须先完整运行一次Apify模块获取样本数据。否则Make无法识别数据结构,后续步骤找不到可映射的变量。
Step 4: 处理字幕缺失
 设置条件:字幕存在(Exists)
设置条件:字幕存在(Exists)
并非所有YouTube视频都有字幕。如果不设置过滤器,空值写入Notion会导致流程报错。
解决方案:
- 添加Filter模块
- 条件设置为:字幕字段 Exists
- 只有有字幕的视频才继续处理
字幕存储方式
字幕内容通常很长,超过Notion表格属性的字符限制。
正确做法:
- 不能存入Text属性
- 使用
Append a page content方法 - 将字幕作为段落块添加到页面正文
两种实战策略
策略一:历史数据大清洗
配置:
- MaxResults: 500或1000
- dateFilter: thisYear或不设
- 运行方式: 手动单次
目的:一次性建立频道过往视频的完整档案库。
策略二:周期性增量更新
配置:
- MaxResults: 20
- dateFilter: thisWeek
- 排期: 每周日晚上
目的:低成本自动化追踪最新动态,保持知识库常新。
注意事项
在实际部署时容易遇到的”坑”:
-
URL格式必须精准 - 频道链接必须包含
https://,否则Apify报错 -
“先跑一次”的强制逻辑 - 配置Notion映射前必须先运行Apify获取样本数据
-
字幕缺失导致崩溃 - 必须设置Filter过滤无字幕视频
-
Notion单元格字数限制 - 字幕内容必须用Append Page Content写入正文
适用场景
推荐使用的用户
- 自媒体创作者 - 监控竞品频道或寻找选题灵感
- AI应用开发者 - 需要大量视频字幕文本作为数据集
- 知识管理爱好者 - 建立个人化视频知识库
可能不适合的情况
- 对JSON和API完全无概念的零基础用户
- 仅需简单收藏视频的用户(使用YouTube自带功能即可)
常见问题
可以采集多少条视频数据?
通过MaxResults参数可配置,支持20、500、1000等,取决于Apify的使用额度和需求。
如果视频没有字幕怎么办?
需要设置Filter过滤器,判断字幕是否存在。否则空值写入Notion会导致整个流程报错停止。
字幕内容太长怎么存储?
字幕超过Notion表格属性的字符限制,必须使用Append Page Content方法,将其作为段落块添加到页面正文中。
支持定时自动更新吗?
支持。可以设置每周运行一次,配合thisWeek过滤器实现增量更新,低成本保持知识库常新。
下一步
学会了基础工作流后,你可以尝试:
- 添加AI摘要模块自动生成视频总结
- 集成翻译API处理多语言字幕
- 添加更多频道监控
- 设置通知提醒新视频
有问题欢迎在评论区留言交流!
常见问题
- 可以采集多少条视频数据?
- 通过MaxResults参数可配置,支持20、500、1000等,取决于Apify的使用额度和需求。
- 如果视频没有字幕怎么办?
- 需要设置Filter过滤器,判断字幕是否存在。否则空值写入Notion会导致整个流程报错停止。
- 字幕内容太长怎么存储?
- 字幕超过Notion表格属性的字符限制,必须使用Append Page Content方法,将其作为段落块添加到页面正文中。
- 支持定时自动更新吗?
- 支持。可以设置每周运行一次,配合thisWeek过滤器实现增量更新,低成本保持知识库常新。